|
Older posts Newer posts Why D?
September 19, 2014
If you look at stuff on this site you'll notice a trend: newer apps tend to be written in D
programming language. There's a photo editing app,
disk space visualizer and analyzer,
a tool for automatic video processing,
a tool for reading DirectShow graph files as text,
all in D (and all free and open source btw).
We also have many small internal tools written in D, even this very blog is powered by a hundred
lines of D now.
One of our main products, a video processing app called Video Enhancer, is currently written in C++
but the next major version is going to be in D for most parts except for
the heavy number crunching bit where we need the extremes of performance only reachable by
C++ compilers today.
So obviously I must like D, and here are my personal reasons for doing it:
Read more...
tags: programming
Recursive algebraic types in D
September 15, 2014
One of the things D programming language seemingly lacks is support for algebraic data types
and pattern matching on them. This is a very convenient kind of types which most functional
languages have built-in (as well as modern imperative ones like Rust or Haxe). There were
some attempts at making algebraic types on the library level in D (such as Algebraic template
in std.variant module of D's stdlib) however they totally failed their name: they don't support
recursion and hence are not algrabraic at all, they are sum types at best. What follows is
a brief explanation of the topic and a proof of concept implementation of recursive algebraic
types in D.
Read more...
tags: programming
On Robin Hood hashing
September 13, 2014
Recently I played a bit with Robin Hood hashing, a variant of open addressing
hash table. Open addressing means we store all data (key-value pairs) in one big
array, no linked lists involved. To find a value by key we calculate hash for the key,
map it onto the array index range, and from this initial position we start to wander.
In the simplest case called Linear Probing we just walk right from the initial position
until we find our key or an empty slot which means this key is absent from the table.
If we want to add a new key-value pair we find the initial position similarly and
walk right until an empty slot is found, here the key-value pair gets stored.
Robin Hood hashing is usually described as follows. It's like linear probing,
to add a key we walk right from its initial position (determined by key's hash)
but during the walk we look at hash values of the keys stored in the table
and if we find
a "rich guy", a key whose Distance from Initial Bucket (DIB) a.k.a. Path
from Starting Location (PSL) a.k.a. Probe Count is less than the distance we've
just walked searching, then we swap our new key-value pair with this rich guy
and continue the process of walking right with the intention to find a place
for this guy we just robbed, using the same technique. This approach decreases
number of "poors", i.e. keys living too far from their initial positions and
hence requiring a lot of time to find them.
When our array is large and keys are scarce, and a good hashing function distributed
them evenly so that each key lives where its hash suggests (i.e. at its initial
position) then everything is trivial and there's no difference between linear probing
and Robin Hood. Interesting things start to happen when several keys have the same
initial position (due to hash collisions), and this starts to happen very quickly -
see the Birthday Problem. Clusters start to appear - long runs of consecutive
non-empty array slots.
For the sake of simplicity let's take somewhat exaggerated
and unrealistic case that however allows to get a good intuition of what's happening.
Imagine that when mapping hashes to array index space 200 keys landed onto [0..100]
interval while none landed onto [100..200]. Then in the case of linear probing it
will look like this:
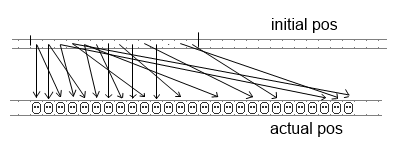
Read more...
tags: programming
D as a scripting language
September 12, 2014
Many of us encounter small tasks involving some file operations, text processing and
running other processes. These are usually solved using either shell or glue
languages (often called scripting languages because of this) like Python, Perl
or Ruby. Compiled statically typed languages are rarely used in such cases
because popular ones usually require too much effort to write and run a simple
script. However some static languages can actually be used here easily instead
of scripting ones, providing their usual benefits such as checking for types and
typos. Here's an example of using D in such scenario.
Earlier this year I discovered a nice tool called
TimeSnapper that sits in background
and saves everything that happens on your screen by doing screenshots on regular
time intervals. It can also collect some stats about apps you run and sites you
browse. During first month I used this feature in the demo version and proved
my suspicion that I waste way too much time on reddit and LiveJournal. ;) Later I
switched to free version of TimeSnapper that doesn't collect and report stats
but just makes the screenshots and allows playing them like a video with timeline.
This serves me as a precise visual memory so that later I can always see what happened
at certain moments. Found a weird unwanted shortcut on my desktop, what app placed it
here? Quick look at its creation time, replay what I was doing then, ah, here's
the thing I was installing at that moment. Here's a library I built on day X, but in
which project was I using it? Replay that hour, see the opened project, ah, now I
remember.
Read more...
tags: programming
Special treatment for Deshaker
May 27, 2014
There is a nice filter for VirtualDub (supported by Video Enhancer) called Deshaker
by Gunnar Thalin which can stabilize shaky video. This filter is different from the others
because it works in two passes: first it needs to see the whole video and analyze it
(without producing a meaningful video result yet), and on the second pass it uses collected
data to actually fix the video. The data collected in first pass is stored in a file
which can be specified in filter's options. If you start analyzing another file
previously collected data is erased. This means up to recently Deshaker could not be used
in Video Enhancer's batch mode where you select many files and apply a sequence of filters
to all of them. Because in that filter sequence Deshaker will be configured for either first
or the second pass while each file requires going through both passes one right after another.
To fix this issue we've added in Video Enhancer 1.9.10 special treatment for Deshaker:
when you start processing some video file and your sequence of filters contains Deshaker
then Video Enhancer first makes one pass in preview (without compression and writing to disk)
and then immediately processes the file
again but this time automatically switching Deshaker to second pass. And if you're processing
a bunch of files then this approach applies to each of them: for each file Video Enhancer
will do two passes: quick preview with Deshaker in first pass then actual processing with
Deshaker in second pass.
Of course, if your chain of filters does not contain Deshaker then Video Enhancer works
as usual: just one pass for each file.
tags: video_enhancer
New Super Resolution is ready.
December 13, 2013
This year we explored ways to accelerate and improve our Super Resolution engine,
and overall research, development and testing took much more time than we anticipated
but finally the new engine is available to our users. Today we're releasing it in
a form of VirtualDub plugin. DirectShow filter
is also ready, so after we change Video Enhancer to use the new version there
will be an update for Video Enhancer too. Also, an AviSynth plugin will be released soon.
Our advances in speed allow using it in video players to upsize videos to HD in
real time on modern PCs and laptops.
Generally quality and speed depend on source video and your CPU'a abilities, but here's
an example of changes between our old VirtualDub plugin (1.0) and the new one (2.0) on
a particular file (panasonic4.avi) when upsizing from 960x540 to 1920x1080 on an old
Quad Core 2.33 GHz:
Quality, in dB of Y-PSNR (higher is better):
version old new
fast mode 41.70 42.28
slow mode 42.07 42.73
Time of upsizing 200 frames, in seconds:
version old new_rgb new_yv12
fast mode 19.6 14.4 10.3
slow mode 28.7 19.5 14.0
Version 1.0 worked only in RGB32, so for YUV the speed was about the same as for RGB.
As you may see, the new version's fast mode provides similar quality to old version's
high-quality mode but does it 2-3 times faster depending on color space. And new
version's high-quality mode is still faster than old one's fast mode.
To achieve these speed gains our SR implementation was rewritten from scratch
to work block-wise instead of frame-wise. This way it doesn't need so much memory
to store intermediate results and intermediate data never leaves CPU cache,
avoiding spending so much time on memory loads and stores. Also, we learned to
use SSE2 vector operations better. Unfortunately even in 2013 compilers
still generally suck at vectorizing code, so it requires a lot of manual work.
tags: video_enhancer super_resolution
Working with raw video data in C# with DirectShow
October 19, 2013
Too many questions arising on different forums and emails I see revolve around
one theme: how do I access actual video data in a DirectShow app? People want to
save images from their web cams, draw something in the video, analyse it, etc.
But in DirectShow direct work with raw data is encapsulated and hidden inside filters,
the building blocks out of which we build DirectShow graphs. So when dealing with DirectShow
we've got a bunch of filters on our hands and we tell them what to do but we don't
get the actual raw bytes of audio/video data, hence multiple questions, because there
isn't always a suitable filter that does exactly what you need. In some cases we're forced
to create our own filter, but that may be rather complicated and tedious. However many
cases can be solved by using one standard filter which is part of DirectShow itself:
Sample Grabber.
Here's an example of using it to implement a video effect and apply it to a stream of video
from a web camera.
This short tutorial will basically repeat my previous post but this time we'll use C#
instead of C++.
Read more...
tags: directshow
Accessing raw video data in DirectShow
October 18, 2013
In DirectShow one makes multimedia apps by building graphs where nodes (called filters)
process the data (capture or read, convert, compress, write etc.) and graph's edges are streams
of multimedia samples (video frames, chunks of audio, etc.). All the work with raw data
takes place inside the filters, and the host application usually doesn't deal with video/audio
data directly, it only arranges the filters in a graph telling them what to do. This is fine
for some typical tasks when you've got all necessary filters, but sometimes there is no ready
made filter for your task and then you need to create your own filter which may be rather
tedious and complicated. However there are many cases when you only want to peek at the data,
analyse or save some part of it, you don't want a transform that changes media type, so making
your own filter is an overkill. There is a nice standard filter in DirectShow which can
give you access to raw video data (let's stick with just video for now) without creating
your own filters, it's called
Sample Grabber.
MSDN says it's deprecated, but this filter is still available in all versions of Windows
including Windows 8. Even if it goes away some time in the future, recreating it will be very
easy, so your program will not need to change.
In this little tutorial I'll show how to make a small DirectShow app in C++ which takes video
stream from USB camera, applies a simple video effect (accessing raw video data) and shows it
on screen. The idea is simple: make a graph where video stream flows from the camera through
sample grabber to a video renderer. Each time a frame passes the sample grabber it calls my
callback where I manipulate with raw video data before it's sent down the stream for
displaying.
Read more...
tags: directshow
Status report and plans
September 21, 2013
It's been a while since last Video Enhancer version was released. It's time to
break the silence and reveal some news and plans.
Part of the passed year
was spent on ScreenPressor-related projects for our corporate clients.
But for last several months we've been cooking our new super resolution engine.
It's not on GPU yet but we've found a way to accelerate it on CPU and use
significantly less memory. Actually, reducing memory usage is the key to
acceletarion: nowadays memory access is quite slow compared to computations,
and if you compute everything locally in small chunks that fit into cache
and don't store and read whole frames in memory several times, overall process
gets much faster. For us that meant a complete rewrite of our super resolution
engine, and this is what we did. While remaking the algorithm we had a chance
to rethink many decisions baked into it. Additional CPU cycles freed by
the acceleration could be spent to perform more computations and reach for
higher quality. So we spent several months in research: what motion estimation
method works best for our SR? Shall we work in blocks of size 16, 8 or even 4
pixels wide (the latter meaning just 2x2 blocks of original image)?
Which precision to use for each block size? What is the right way
to combine new frame with accumulated information? For motion estimation we
actually tried it all: using source code generation we generated 160 different
implementations of motion estimation and measured how well they performed
in terms of quality and speed. It turned out usual metrics for selecting
best motion compensation methods in video codecs and other applications do
not give the best results for super resolution: minimizing difference between
compensated and current frame (which works best for compression) doesn't
provide best quality in SR when compensated frame gets fused with input
frame to produce the new upsized image. Then the fusion: is our old method
really good or maybe it can be improved? We used machine learning techniques
to find the best fusion function. And found that actually it depends a lot
on source video: what works best for one video doesn't necessarily work well
for another video. We chose a weighted average for a selected set of HD videos
which means quality of the new SR engine should be higher on some videos
and possibly a bit lower on some other videos, it won't be universally
better.
Now what it all means in terms of releases. The new SR engine is in final
testing stage now and it's a matter of days before it's released in
Video Enhancer 1.9.9 and new version of our Super Resolution plugin for
VirtualDub. Then it will also be released as AviSynth plugin, for the first
time. And then finally it will come as Adobe After Effects (and Premiere Pro,
probably) plugin. Some years ago we offered this Premiere Pro & After Effects
plugin but it hadn't updated for too long and became obsolete, current
versions of these Adobe hosts are 64-bit and cannot run our old 32-bit plugin.
Video Enhancer 1.9.9 will be a free update, and it's going to be the last
1.x version. Next release will be version 2.0 with completely different
user interface, where all effects will be visible instantly. Imagine
"Photoshop for video". Update to 2.0 will be free for those who purchased
Video Enhancer 1.9.6 or later.
We hope everything mentioned above will see the light this year.
VE 1.9.9 in September, plugins in October, VE 2.0 later.
Update: oops, our scheduling sucks as usual. YUV support and thorough
testing took much more time, the releases postponed until December.
tags: video_enhancer super_resolution
Writing AVI files with x264
Seprember 26, 2012
x264 is an excellent video codec implementing H.264 video compression standard.
One source of its ability to greatly compress video is allowing a compressed
frame to refer to several frames not only in the past but also in the future:
refer to frames following the current one. Such frames are called B-frames (bidirectional),
and even previous generation of video codecs, MPEG4 ASP (like XviD), had this feature,
so it's not particularly new. However AVI file format and Video-for-Windows (VfW)
subsystem predate those, and are designed to work strictly sequentially: frames
are compressed and decomressed in strict order one by one, so a frame can only
use some previous frames to refer to. Such frames are called P-frames (predicted).
For this
reason AVI format does not really suit MPEG4 and H.264 video. However with some
tricks (or should I say hacks) it is still possible to write MPEG4 or H.264 stream
to AVI file, and this is what VfW codecs like XviD and x264vfw do. They buffer some
frames and then output compressed frames with some delay, sometimes combining P and B
frames in single chunks. Appropriate decoder knows this trick and restores proper
frame order so everything works fine.
Some time ago we received a complaint from a user of Video Enhancer about x264vfw:
video compressed with this codec to AVI file showed black screen when started playing
and only after jumping forward a few seconds it started to play, but with sound out
of sync. To investigate the issue I made a graph in GraphEditPlus where some video
was compressed with x264vfw and then written to an AVI file. But I also inserted
a Sample Grabber right after the compressor to see what it outputs. Here's what I got:
click to enlarge
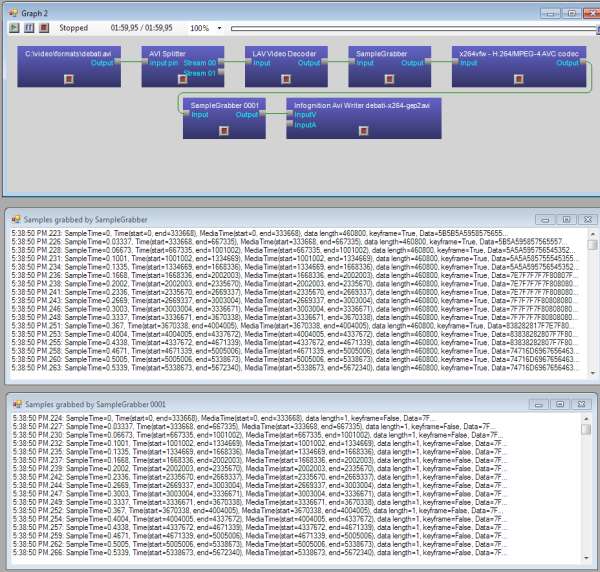
It turned out for some reason x264vfw spitted ~50 empty frames, 1 byte in size each,
all marked as delta (P) frames. After those ~50 frames came first key frame and then
normal P frames of sane sizes followed. Those 50 empty frames which were not started
with a key frame (like it is expected to be in AVI file) created the effect: black
screen when just started playing and audio sync issue. I don't know in what version
of x264vfw this behavior started but it's really problematic for writing AVI files.
Fortunately, the solution is very simple. If you open configuration dialog of
x264vfw you can find "Zero Latency" check box. Check it, as well as "VirtualDub hack"
and then it will work properly: will start sending sane data from the first frame,
and resulting AVI file will play fine.
tags: video_enhancer directshow
Older posts Newer posts
| 
 RSS
RSS